Flex与Bison基础概念介绍
Flex介绍
Flex和Bison都是用来生成程序的工具。编译器的工作主要可以分解成两个方面:词法分析与语法分析
- 词法分析(lexical analysis 或Scanning): 将输入分割成一个个有意义的词块,称之为记号
token - 语法分析(syntax analysis 或prsing): 这是确定这些记号是如何彼此关联的。
一个小的例子:
alpha = beta + gamma;
词法分析器是将这些代码分解成一些token: alpha, 等号, beta, 加号, gamma和分号。接下来语法分析器就需要确定beta + gamma是一个表达式,而这个表达式被赋值给了alpha。
Flex例子
第一个简单的Flex例子
我们使用flex来实现一个文件的行数,单词数和字符数统计程序。包含两个文件main.cpp以及flex语言的scan.l。
Flex部分的程序代码
首先介绍scan.l程序,介绍程序之前我们需要先了解一些flex的语法。Flex的程序主要包含三个部分,各个部分之间使用仅有的%%来进行分隔。
- 第一部分:包含声明和选项设置
- 第二部分:包含一些力的模式和动作
- 第三部分:这部分是
C代码,会被拷贝到生成的词法分析器(对应代码是由scan.l文件转换得到的lex.yy.c)里面的最后的位置。
%{
#include <iostream>
int lines = 0;
int words = 0;
int chars = 0;
%}
word [a-zA-Z]+
%%
{word} { ++words; chars += strlen(yytext); }
"\n" { ++lines; ++chars; }
. { chars += strlen(yytext); }
%%
int yywrap() { return 1; }
在第一部分的%{ }%之间代码会被拷贝到C文件lex.yy.c文件的开头部分。
第二部分,每个模式在第一行的开头位置,而后面是模式匹配时所需要执行程度C代码。这里的C代码就是{和}之间的一行或者多行代码。
模式必须在行首出现,因为Flex会把空白开始的行都是代码而把它们复制到生成的c程序中
说明. { chars += strlen(yytext); }这个位置使用了一个变量yytext,这边变量总是被设置为指向本次匹配的输入文本。
第三部分的代码,是直接拷贝到lex.yy.c文件的最后一部分的:
接下来编译这个文件,编译的时候,使用flex对应的库文件-lfl进行链接。
flex scan.l
gcc lex.yy.c -lfl
Main函数实现最后的打印功能
在Main()函数里面,我们调用flex提供的词法分析例程yylex(),
#include <iostream>
int yylex();
extern int words;
extern int lines;
extern int chars;
int main() {
yylex();
std::cout << "words: " << words << std::endl;
std::cout << "lines: " << lines << std::endl;
std::cout << "chars: " << chars << std::endl;
return 0;
}
运行结果,使用wc命令进行对比判断:

在这里我们为了方便可以使用Markfile来进行编译的管理,Makefile文件如下:
CCC = g++
LEX = flex
CFLAGS = -Wall
LEXFLAGS = -Wno-unused
OBJS = main.o lex.yy.o
run: $(OBJS)
$(CCC) $(CFLAGS) -o run $(OBJS)
main.o: main.cpp
$(CCC) $(CFLAGS) -c main.cpp
lex.yy.c: scan.l
$(LEX) scan.l
lex.yy.o: lex.yy.c
$(CCC) $(CFLAGS) $(LEXFLAGS) -c lex.yy.c
clean:
rm -f run *.o lex.yy.c
这个例子的官方实现情况
scan.l文件:
%{
/* TERMINOLOGY: A "word" is a set of non-delimiters seperated by delimiters.
* -- edge case 1: files with a word and no delimiters
* -- edge case 2: last word of the file
* -- edge case 3: leading delimiters
* -- edge case 4: files with only delimiters
*
* A "line" is a newline character \n.
* -- Weirdly, a file written on one line with no newline
* character at the end is considered to have ZERO lines
*
* A "char" is ANY character in the file (delimiters and non-delimiters).
*/
#include <iostream>
#include <cstring>
int words = 0; // count of words
int chars = 0; // count of chars
int lines = 0; // count of lines
%}
%option noinput
%option nounput
/* definition of characters that DO NOT compose words
* ~ spaces, tabs, and newlines
*/
delimiter [ \t\n]
/* definition of characters that DO compose words
* ~ everything but spaces, stabs, and newlines
*/
letter [^ \t\n]
%%
/* This rule is for the edge-case that delimiters appear
* at the front of the file or the file has only delimiters.
*/
{delimiter}+ {
chars += strlen(yytext);
for(int i = 0; yytext[i]; ++i)
if(yytext[i] == '\n') ++lines;
}
/* This rule is for typical cases, files with one word
* and no delimiters, and the last word of the file.
*
* Note that we use the closure set of delimiters, not the
* the positive closure set. What would happen if we made this change?
*/
{letter}+{delimiter}* {
++words;
chars += strlen(yytext);
for(int i = 0; yytext[i]; ++i)
if(yytext[i] == '\n') ++lines;
}
%%
int yywrap() { return 1; }
main.cc文件:
#include <iostream>
int yylex();
extern int words;
extern int lines;
extern int chars;
int main() {
yylex();
std::cout << std::endl << "~~~~~~~~~~" << std::endl;
std::cout << "lines: " << lines << std::endl;
std::cout << "words: " << words << std::endl;
std::cout << "characters: " << chars << std::endl;
return 0;
}
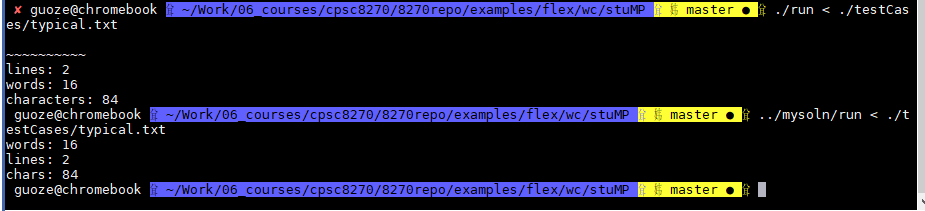
输出结果对比:
使用Flex和Bison协同工作—计算器
语法分析器是找出输入记号之间的关系,最常见的关系就是语法分析树(parser tree)
Scan.l文件协同工作原理分析
scan.l文件,在处理用户输入的数学方程式的时候,我们为了处理简单,这里只考虑识别整数,基本算术运算符。
词法分析器与语法分析器协同工作 使用词法分析器获得一个记号流,然后将这个记号流传递给其他程序,每当产生一个记号之后,就调用yylex()来读取当前匹配到的输入然后返回去相应的记号。当程序需要下一个记号的会后,需要再次调用yylex(). 注明:词法分析器以协同程序的方式进行运行,每次它返回的手,就会记住当前处理的位置,并从这个位置开始去处理下一次的调用。 如果这次匹配不需要产生记号,那么词法分析器就会在这次yylex()调用中继续分析接下来的输入字符。
特点:如果动作有返回,那么词法分析器就会在下一次yylex()调用中继续;如果动作没有返回,词法分析器就会立即继续进行。
%{
#include "parse.tab.h"
%}
%%
"+" { return PLUS; }
"-" { return MINUS; }
"*" { return MULT; }
"/" { return DIV; }
[0-9]+ {
return NUMBER;
}
"\n" { return CR; }
<<EOF>> { yyterminate(); }
%%
int yywrap() {
yylex_destroy();
return 1;
}
在这个程序中,我们可以看到出现的记号为:PLUS, MINUS, MULT, DIV, NUMBER, CR, EOF,这些记号是在parse.tab.h这个文件中生成的,而这个文件是根据parser.y的bison文件生成出来的。这些记号是对应了一个记号编号和记号值的。记号编号是一个较小的整数,随机生成的,但是0意味的是文件的结束。

如果我们想完全在flex里面实现输出,那么也可以使用enum来定义记号数值编号。
Bison部分工作
Bison的程序包含了与Flex程序相同的三部分结构:声明部分,规则部分和C代码部分。
- 声明部分:包含了会被原样拷贝到目标分析程序开头的C代码,通过
%{ 和 }%来声明,之后是%token记号声明,用于告诉bison在语法分析器里面记号的名称。 (潜规则:记号使用大写字母)在第二部分中,任何没有在这里声明为记号的语法符号必须出现在至少一条规则的左边 - 第二部分,通过简单的BNF定义的规则。 Bison使用
:来分割,使用;来表示规则的结束。如果有C代码,那就需要在两个{与}之间。
%{
#include <iostream>
extern int yylex();
extern int yylval;
void yyerror(const char * msg);
%}
%token CR NUMBER PLUS MINUS MULT DIV
%%
lines : lines expr CR
{ std::cout << "result: " << $2 << std::endl; }
| lines CR
|
;
expr : expr PLUS term
{ $$ = $1 + $3; }
| expr MINUS term
{ $$ = $1 - $3; }
| term
{ $$ = $1; }
;
term : term MULT factor
{ $$ = $1 * $3; }
| term DIV factor
{ $$ = $1 / $3; }
| factor
{ $$ = $1; }
;
factor : NUMBER
;
%%
void yyerror(const char * msg) { std::cout << msg << std::endl; }
#include <iostream>
extern int yyparse();
int main() {
if ( yyparse() ) {
std::cout << "syntactically correct program" << std::endl;
}
return 0;
}
Terry Tang
Software Development Engineer
My research interests include distributed robotics, mobile computing and programmable matter.