Linux内核分析课程8_进程调度与进程切换过程
Linux内核课第八周作业。本文在云课堂中实验楼完成。 原创作品转载请注明出处 《Linux内核分析》MOOC课程
一.schedule()函数介绍
1.进程调度的时机
中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();
内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
2.进程的切换
为了控制进程的执行,内核必须有能力挂起正在CPU上执行的进程,并恢复以前挂起的某个进程的执行,这叫做进程切换、任务切换、上下文切换;
挂起正在CPU上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是由用户态转向内核态执行;
进程上下文包含了进程执行需要的所有信息:
- 用户地址空间: 包括程序代码,数据,用户堆栈等
- 控制信息: 进程描述符,内核堆栈等
- 硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同)
3.具体进程切换的代码分析
schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换:
主要调用过程:
- next = pick_next_task(rq, prev);//进程调度算法都封装这个函数内部
- context_switch(rq, prev, next);//进程上下文切换
- switch_to利用了prev和next两个参数:prev指向当前进程,next指向被调度的进程
1)schedule()函数
首先,切换时候,调用call schedule();来执行schedule()函数,如下图所示:

使用struct task_struct *tsk = current; 来获取当前进程;sched_submit_work(tsk); 避免死锁;最后调用_schedule()来处理切换过程
2)_schedule()函数
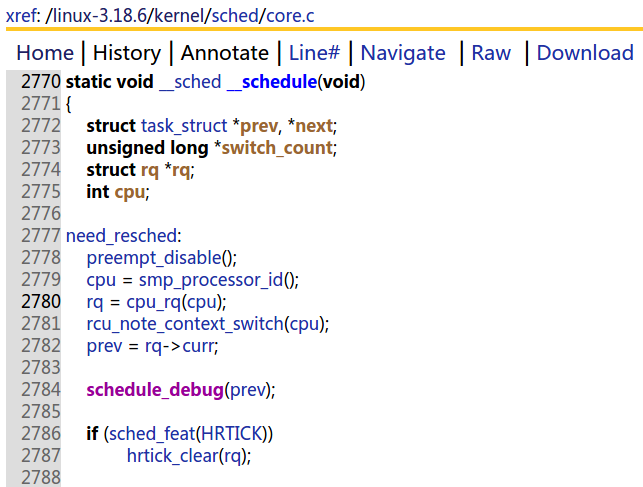
其中 need_resched:为切换前的变量准备:
preempt_disable();//禁止内核抢占;
cpu = smp_processor_id(); //获取当前CPU
rq = cpu_rq(cpu); //获取该CPU维护的运行队列(run queue)
rcu_note_context_switch(cpu); //更新全局状态,标识当前CPU发生上下文的切换
prev = rq->curr; //运行队列中的curr指针赋予prev。

其中的next=pick_next_task(rq, prev)来确定使用哪一种进程调度的策略,但总是选择了下一个进程来进行切换,即根据调度策略选择一个优先级最高的任务将其定为下一个进程,最后都是调用context_switch来进行进程上下文的切换过程.
3)context_switch函数解析

其中prepare_task_switch()函数是完成切换前的准备工作;接着后面判断当前进程是不是内核线程,如果是内核线程,则不需要切换上下文

接着调用switch_mm(),把虚拟内存从一个进程映射切换到新进程中
调用switch_to(),从上一个进程的处理器状态切换到新进程的处理器状态。这包括保存、恢复栈信息和寄存器信息
如果next是内核线程,则线程使用prev所使用的地址空;schedule( )函数把该线程设置为懒惰TLB模式
事实上,每个内核线程并不拥有自己的页表集(task_struct->mm = NULL);更确切地说,它使用一个普通进程的页表集。不过,没有必要使一个用户态线性地址对应的TLB表项无效,因为内核线程不访问用户态地址空间。

如果next是一个普通进程,schedule( )函数用next的地址空间替换prev的地址空间
|————————————–| | } else | | switch_mm(oldmm, mm, next); | |————————————–|
如果prev是内核线程或正在退出的进程,context_switch()函数就把指向prev内存描述符的指针保存到运行队列的prev_mm字段中,然后重新设置prev->active_mm

context_switch()最后调用switch_to()执行prev和next之间的进程切换了 |———————————-| | switch_to(prev, next, prev); | |———————————-| return prev; }
4)switch_to()函数解析

switch_to(prev, next, prev):切换堆栈和寄存器的状态.

switch_to是一个宏定义,完成的工作主要是:
(1)保存当前进程的flags状态和当前进程的ebp
"pushfl\n\t" /* save flags */
"pushl %%ebp\n\t" /* save EBP */
(2)完成内核堆在esp的切换
"movl %%esp,%[prev_sp]\n\t" /* save ESP */
"movl %[next_sp],%%esp\n\t" /* restore ESP */
进程切换的时候,要修改堆栈,eip等数据.在switch_to中完成了这个工作。
(3)保存eip的值
"movl $1f,%[prev_ip]\n\t" /* save EIP */ \
"pushl %[next_ip]\n\t" /* restore EIP */ \
将标号1:的地址保存到prev->thread.ip中,然后下一次该进程被调用的时候,就从1的位置开始执行。
注明:如果之前next也被switch_to出去过,那么next->thread.ip里存的就是下面这个1f的标号,但如果next进程刚刚被创建,之前没有被switch_to出去过,那么next->thread.ip里存的将是ret_ftom_fork,即进程刚刚被fork后执行exec.
(4)jmp __switch_to
让参数不压入堆栈,而是使用寄存器传值,来调用__switch_to eax存放prev,edx存放next。
二.gdb跟踪schedule函数
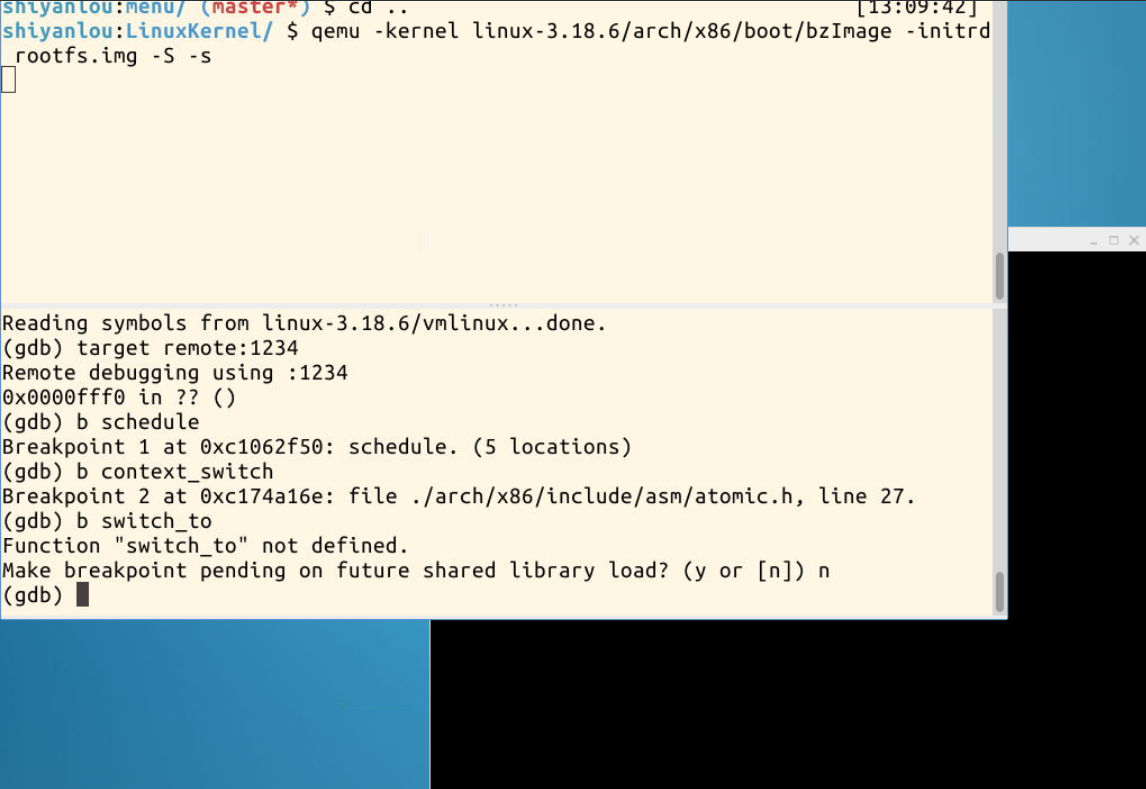
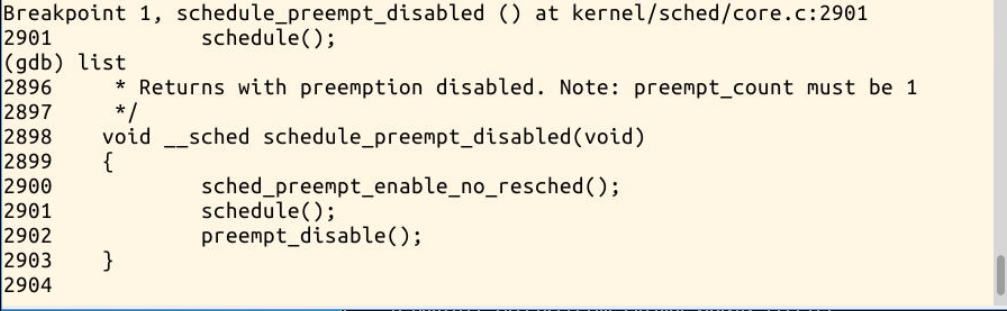
小结:整个schedule的执行过程如下图所示
|———————————-|
schedule
sched_submit_work(tsk)
_schedule()
pick_next_task
context_switch(rq,prev,next)
prepare_task_switch
判断是不是内核线程
switch_mm
switch_to
_switch_to
finish_task_switch
Terry Tang
Software Development Engineer
My research interests include distributed robotics, mobile computing and programmable matter.